Simple Web Theory
When we installed ASP.NET in Chapter 1, the
installation was broken down into stages because we installed several different
pieces of software. One of these pieces of software was the web server, whose
main job is to make your web pages available to everyone. Another job of the
web server is to provide an area (typically in a directory or folder structure)
in which to organize and store your web pages, or whole web site.
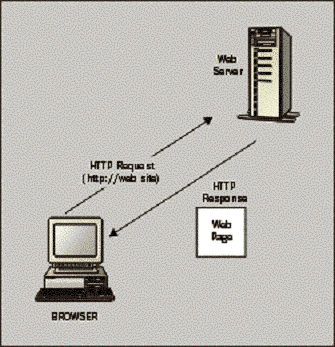
When you use the Web to view a web page,
you will automatically make contact with a web server. The process of
submitting your URL is called 'making a Request' to the server. The server
interprets the URL, locates the corresponding page, and sends back the code to
create the page as part of what is called the Response to the browser. The browser then takes the code it has received
from the web server and compiles a viewable page from it. The browser is
referred to as a client in this
interaction, and the whole interaction as a client-server
relationship.
The term client-server describes the workings of the Web, by outlining the distribution of tasks. The
server (the web server) stores, interprets, and distributes data (that is
compiled into web-pages), and the client (browser) accesses the server to get
at the data. From now on, whenever we use the term client, we are
just referring to the browser.
To understand what is going on in greater
detail, we need to briefly discuss how the client and server communicate over
the Internet using the HTTP protocol.
The HTTP Protocol
The Internet is a network of interconnected nodes. It is designed to carry information from one place to another. When the user tells the browser to fetch
a web page, a message is sent from the browser to the web server.
This message is sent using Hypertext
Transfer Protocol (or HTTP). HTTP is the protocol used by the World Wide Web in
the transfer of information from one machine to another. When you see a URL
prefixed with http://, you know
that the Internet protocol being used is HTTP, as HTTP is the default protocol
used by web browsers. This means if we type www.wrox.com,
the browser will automatically use the HTTP protocol and search for http://www.wrox.com.
The message passed from the browser to the
web server asking for a particular web page is known as an HTTP
Request. When the web server receives this request, it checks its
stores to find the appropriate page. If the web server finds the page, it
bundles up the HTML in an HTTP Response, and sends this back across the network to the browser. If the web
server cannot find the requested page, it issues a response that features an
appropriate error message, and dispatches that
page to the browser.
Here's an illustration of the process, as
we understand it so far:
HTTP is known
as a stateless protocol. This is because it doesn't know whether the
request that has been made is part of an ongoing correspondence or just a
single message, just the same way your postman won't know whether your letter
is the first asking your local hi-fi company for a refund, or the fifteenth.
The reason HTTP is stateless is that it was
only intended to retrieve a single web page for display. Its purpose was to
handle simple transactions, where a user requests a web page, the browser
connects to the requisite web server, retrieves that web page, and then shuts
down the connection. The Internet would be very slow and might even collapse if
permanent connections needed to be maintained between browsers and servers as
people moved from one page to another. Think about the extra work HTTP would
have to do if it had to worry about whether you had been connected for one
minute or whether you had been idle for an hour, and needed disconnecting. Then
multiply that by a million for all the other users. Instead, HTTP makes the
connection and delivers the request, and then returns the response and
disconnects. However, the downside of this is that HTTP can't distinguish
between different requests, and can't assign different priorities, so it won't
be able to tell whether a particular HTTP Request is the request of a user, or
the request of a virus infected machine, that might have been set up, for
instance, to hit a government web server 1,000 times an minute. It will treat
all requests equally, as there are no ways for HTTP to determine where the
request originated.
If a request is
successful, the HTTP Response body contains the HTML code (together with any
script that is to be executed by the browser), ready for the browser to use.
Additional HTTP Requests are used to retrieve any other resource, such as
images, dictated by the HTML code returned after the first request.
Where ASP.NET Fits in with the
.NET Framework
In the last
chapter, we encountered some of the major concepts involved in the .NET
Framework. In this chapter, we've already gained a better understanding of how
a browser sends a web page request, and how the web server sends the page back
to the browser. What we're going to do now is to tie the two together, as this
will help us understand what is happening when we use forms and server-side
controls.
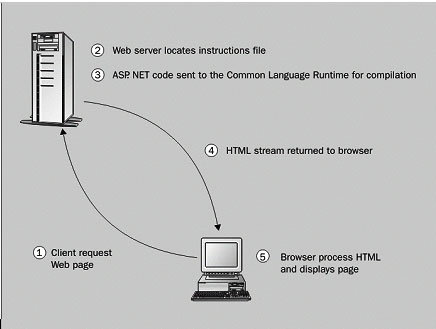
Let's sum up the five step process for delivering a web page:
1.
The client requests a web page.
2. The web server needs to locate the page
that was requested; and if it's an ASP.NET page then this code will need to be
processed in order to generate the HTML that is returned to the browser.
3.
If the name of the web page is
suffixed with .aspx, the server
sends it to the aspnet_isapi.dll (which is attached to the web server) for processing. The aspnet_isapi.dll doesn't actually do much itself, it just forwards the ASP.NET code
to the Common Language Runtime. We looked at what role this performs in the
last chapter, and here we'll just treat it as a black box. If the ASP.NET code
hasn't been compiled before, it is compiled and then executed, and pure HTML
comes out at the other end. In this way the HTML is created dynamically.
4.
The HTML stream is returned to the
browser.
5. The browser displays the web page.
There are a lot of advantages to generating
a page dynamically: you can return information to the user based on their
responses in a form, you can customize web pages for a particular browser, you
can personalize information (and utilize a particular profile for each
individual), and much more beyond the static text and graphics that pure HTML
returns. This is down to the fact that the code we write is interpreted at the
time it is requested.
Now we have a basic understanding of how
the web works, it's time to get stuck into forms. We'll begin by looking at
HTML forms, as they are often much misunderstood. Also, once you know about
HTML forms, the ASP.NET server controls begin to look familiar, as the HTML
form controls perform many of the same functions as their server-side
counterparts.

Buy Beginning ASP.NET with C# here
© Copyright 2002 Wrox Press
This chapter is written by David Sussman, et al
and taken from "Beginning ASP.NET with C#" published by Wrox Press Limited in June 2002; ISBN 1861007345; copyright © Wrox Press Limited 2002; all rights reserved.
No part of these chapters may be reproduced, stored in a retrieval system or transmitted in any form or by any means -- electronic, electrostatic, mechanical, photocopying, recording or otherwise -- without the prior written permission of the publisher, except in the case of brief quotations embodied in critical articles or reviews.
|
|